3.1.81 Detailed description of issue
{Description here}
I rendered a PDF file using the Viewer.js script. Than I created a javascript function that extracts from the spans tag elements on the web page the text that were rendered. But sometimes the text is not readable. For some rease, that I do not understand yet, the text from the PDF is well rendered on the web page and is readable. But when I go to the web page html source the text information is unreadable. It seems to be a byte sequence or non-ascii characters. What I want is to select with the mouse an excerpt from the text already rendered and then render the selected text and annotations in another web page. But everytime I do this the information is unreadable. Expected behaviour
{Provide a screenshot or description of the expected behaviour}
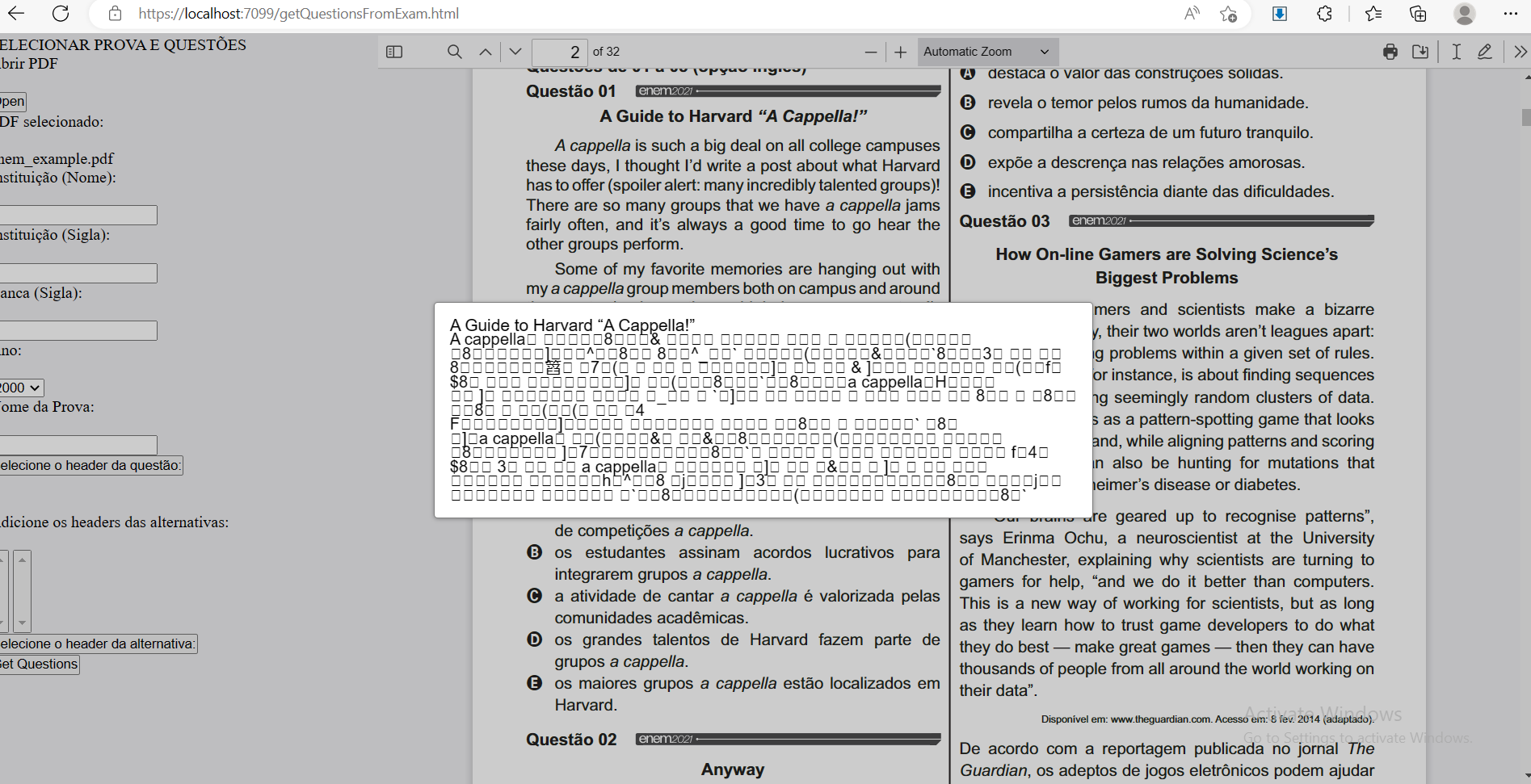
On the screenshot you can see the main windows in the background with the pdf viewrer rendering a pdf. On the forefront there is a modal page with an excerpt from the main page. What I do is to select with my mouse the part of the text I want, use the command window.getSelection(), loop over the selected nodes and extract the information inside textContent. For some reason the text is readable on the main window but it isn´t on the html source.
Does your issue happen with every document, or just one?
{Answer here}
Every document.
Link to document
{Provide a link to the document in question if possible}
Code snippet
{Provide a relevant code snippet}
getQuestions() {
var selection = window.getSelection();
if (selection != null) {
const range = selection.getRangeAt(0);
const nodes = range.cloneContents().childNodes;
var outHTML = "";
var inHTML = "";
var text = "";
if (nodes.length === 1) {
var node = selection.anchorNode;
if (node.nodeType === Node.ELEMENT_NODE) {
outHTML = node.outerHTML;
inHTML = node.innerText;
} else if (node.nodeType === Node.TEXT_NODE) {
var parent = node.parentNode;
outHTML = parent.outerHTML;
inHTML = parent.innerText;
}
} else {
for (const node of nodes) {
outHTML = outHTML + node.outerHTML;
inHTML = inHTML + node.innerText;
}
}
}
const modal = document.getElementById("modal-content");
modal.innerHTML = outHTML;
modal.showModal();
I reproduced the problem using your Demo. Here follows a screenshot.
What I did was the following. I loaded a PDF, using the mouse cursor I selected a sentence on the rendered text, I copied it using Ctrl-C, opened a Notepad with a new text file and then I pasted it using Ctrl-V. You can see on the screen that the text inside Notepad is not readable.
On my own script I do a similar task. I select with the mouse a portion of the text, a click a button that executes a function (the one shown before), this function uses the method window.getSelection(), I get the nodes selected, they are several spans elements in html, from each one I extract the textContent and then I show this information again on a modal html window.
What is happening is the following. When the script viewer.js renders the text from the PDF, it does the correct character mapping using font and glyph information from the texts runs inside the PDF. But for some reason, if you look inside the html source that is loaded by the browser the text is not rendered correctly and it is not readable. It looks like a sequence of binary data.
There is something inside the script viewer.js that does this rendering. I am reading the code but until now I could not figure out where and what it does.
What I want is the following. I want to select a portion of the text rendered with the mouse cursor and then render this text selected in a modal html window. I want to repeat the renderization using only the selected text.
I think that the data that is inside the html source is not the text itself but it is glyph information. I do not understand fully how information is stored inside a PDF file but I suppose that it is. I think what I need to do is to get this glyph information and process it again using the function showText(glyphs) which is inside the script viewer.js.
If you could at least give me some help to know if I am following the right direction it would be nice.
This is not a random pdf file. It is a nation wide exam in Brazil used for more the 4 million people. For some reason the text information does not come from strings in the pdf but from the glyphs. If you change the code inside viewer.js you can identify that the text is drawn from the glyphs information in the function showText(glyphs). But I still do not understand. If the text is a image, why there is a unreadable string as a text information inside the pdf? I tried the getSelectedText and still does not solve the problem. It seems that the unreadable string is really inside the pdf and not caused for some bug in the software. Do you have a clue about why there is this information?
Thank you for your support Kevin. I will do some research on this issue and try to get a good solution. For now I am using an OCR framework to detect text drawn on the canvas.